Welcome to qinghui's blog
这里是我的个人IT学习小天地-
kafka-connector-plugin
- 摘要
- kafka connector 分布式架构说明
- plugin组件介绍
- kafka部署和 plugin组件配置
- 配置Oracle connector
- 配置MySQLconnector
- reset api 的常用命令
摘要
上文已经介绍了如何以插件的方式部署Debezium,可以看到通过kafka connect接口,可以部署和使用丰富的连接器。confluent提供了丰富的connect plugin,包含自研的和一些第三方的plugin,而Debezium开源项目提供针对DB 的connector。所以单纯从功能上来说,通过kafka和connector plugin 实现数据总线,或者数据流成为可能,让数据流动起来。 上文已经部署过了stanalone 模式,本文会着重介绍分布式模式部署kafka connect,并说明Debezium社区开发的所有连接器,以及支持的数据种类。 目前只说明kafka connector source ,为下文展开sink 端的数据导出,本文还会部署confluent 公司开发 jdbc connector,能连接所有提供jdbc连接的数据库,实现数据的导入和导出。
kafka connector 分布式架构说明
Kafka Connect是Kafka 0.9+增加了一个新的特性,提供了API可以更方便的创建和管理数据流管道。它为Kafka和其它系统创建规模可扩展的、可信赖的流数据提供了一个简单的模型,通过connectors可以将大数据从其它系统导入到Kafka中,也可以从Kafka中导出到其它系统。Kafka Connect可以将完整的数据库注入到Kafka的Topic中,或者将服务器的系统监控指标注入到Kafka,然后像正常的Kafka流处理机制一样进行数据流处理。而导出工作则是将数据从Kafka Topic中导出到其它数据存储系统、查询系统或者离线分析系统等,比如数据库、Elastic Search、Apache Ignite等。
plugin组件介绍
- confluentinc-kafka-connect-jdbc-10.2.5.zip jdbc 支持source 和sink debezium-connector-oracle-1.7.0.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-mysql-1.7.0.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-postgres-1.7.0.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-mongodb-1.7.1.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-sqlserver-1.7.1.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-db2-1.7.1.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-vitess-1.7.1.Final-plugin.tar.gz 只支持source,CDC日志采集 debezium-connector-cassandra-1.7.1.Final-plugin.tar.gz 只支持source,CDC日志采集
kafka部署和 plugin组件配置
1、zookeeper 集群部署
--所有节点修改配置文件 vi /app/kafka_2.13-2.8.1/config/zookeeper.properties dataDir=/app/data/zookeeper clientPort=2181 maxClientCnxns=0 admin.enableServer=false tickTime=2000 initLimit=5 syncLimit=2 server.1=10.96.80.31:2888:3888 server.2=10.96.80.32:2888:3888 server.3=10.96.80.33:2888:3888 --设置不同节点的myid echo "1" > /app/data/zookeeper/myid echo "2" > /app/data/zookeeper/myid echo "3" > /app/data/zookeeper/myid --所有节点启动服务 zookeeper-server-start.sh -daemon /app/kafka_2.13-2.8.1/config/zookeeper.properties2、kafka集群配置
--修改配置文件,所有节点 vi /app/kafka_2.13-2.8.1/config/server.properties broker.id=1 listeners=PLAINTEXT://10.96.80.31:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/app/data/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 min.insync.replicas=2 default.replication.factor=3 offsets.topic.replication.factor=3 transaction.state.log.replication.factor=3 transaction.state.log.min.isr=3 log.retention.hours=2 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=10.96.80.31:2181,10.96.80.32:2181,10.96.80.33:2181 zookeeper.connection.timeout.ms=18000 group.initial.rebalance.delay.ms=0 delete.topic.enable=true 节点2 broker.id=2 listeners=PLAINTEXT://10.96.80.32:9092 节点三 broker.id=3 listeners=PLAINTEXT://10.96.80.33:9092 --启动kafka服务 kafka-server-start.sh -daemon /app/kafka_2.13-2.8.1/config/server.properties3、Kafka connect配置和启动
--节点一 vi /app/kafka_2.13-2.8.1/config/connect-distributed.properties bootstrap.servers=10.96.80.31:9092,10.96.80.32:9092,10.96.80.33:9092 group.id=connect-cluster key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false internal.key.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.topic=connect-offsets offset.storage.replication.factor=3 offset.storage.partitions=3 config.storage.topic=connect-configs config.storage.replication.factor=3 status.storage.topic=connect-status status.storage.replication.factor=3 offset.flush.interval.ms=10000 rest.advertised.host.name=10.96.80.31 offset.storage.file.filename=/app/data/connect.offsets plugin.path=/app/kafka_2.13-2.8.1/plugin --节点二 rest.advertised.host.name=10.96.80.32 节点三 rest.advertised.host.name=10.96.80.33 --创建启动必须的topic kafka-topics.sh --create --zookeeper 10.96.80.31:2181 --topic connect-configs --replication-factor 3 --partitions 1 --config cleanup.policy=compact kafka-topics.sh --create --zookeeper 10.96.80.31:2181 --topic connect-offsets --replication-factor 3 --partitions 3 --config cleanup.policy=compact kafka-topics.sh --create --zookeeper 10.96.80.31:2181 --topic connect-status --replication-factor 3 --partitions 1 --config cleanup.policy=compact --启动分布式的connect服务,所有节点 connect-distributed.sh -daemon /app/kafka_2.13-2.8.1/config/connect-distributed.properties4、查询支持 plugins
[kafka@node2 ~]$ curl -s localhost:8083/connector-plugins|jq [ { "class": "io.confluent.connect.jdbc.JdbcSinkConnector", "type": "sink", "version": "10.2.5" }, { "class": "io.confluent.connect.jdbc.JdbcSourceConnector", "type": "source", "version": "10.2.5" }, { "class": "io.debezium.connector.db2.Db2Connector", "type": "source", "version": "1.7.1.Final" }, { "class": "io.debezium.connector.mongodb.MongoDbConnector", "type": "source", "version": "1.7.1.Final" }, { "class": "io.debezium.connector.mysql.MySqlConnector", "type": "source", "version": "1.7.0.Final" }, { "class": "io.debezium.connector.oracle.OracleConnector", "type": "source", "version": "1.7.0.Final" }, { "class": "io.debezium.connector.postgresql.PostgresConnector", "type": "source", "version": "1.7.0.Final" }, { "class": "io.debezium.connector.sqlserver.SqlServerConnector", "type": "source", "version": "1.7.1.Final" }, { "class": "io.debezium.connector.vitess.VitessConnector", "type": "source", "version": "1.7.1.Final" }, { "class": "org.apache.kafka.connect.file.FileStreamSinkConnector", "type": "sink", "version": "2.8.1" }, { "class": "org.apache.kafka.connect.file.FileStreamSourceConnector", "type": "source", "version": "2.8.1" }, { "class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector", "type": "source", "version": "1" }, { "class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector", "type": "source", "version": "1" }, { "class": "org.apache.kafka.connect.mirror.MirrorSourceConnector", "type": "source", "version": "1" } ]配置Oracle connector
需要特别注意,connectors 的建立通过reset api实现
1、创建连接器
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{ "name": "hr-connector", "config": { "connector.class" : "io.debezium.connector.oracle.OracleConnector", "tasks.max" : "1", "database.server.name" : "DB01", "database.hostname" : "10.96.80.21", "database.port" : "1521", "database.user" : "c##dbzuser", "database.password" : "dbz", "database.dbname" : "orcl", "database.pdb.name":"PDB1", "table.include.list" : "hr.test", "database.history.kafka.bootstrap.servers" : "10.96.80.31:9092,10.96.80.32:9092,10.96.80.33:9092", "database.history.kafka.topic": "schema-changes.test" } }'2、检查连接器的状态
[kafka@node1 debezium-connector-cassandra]$ curl -s localhost:8083/connectors/hr-connector/status|jq { "name": "hr-connector", "connector": { "state": "RUNNING", "worker_id": "10.96.80.31:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "10.96.80.31:8083" } ], "type": "source" }配置MySQLconnector
1、创建MySQL 的connector
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{ "name" : "mysql-connector", "config": { "connector.class" : "io.debezium.connector.mysql.MySqlConnector", "database.hostname" : "10.96.80.31", "database.port" : "3307", "database.user" : "dbz_mysql", "database.password" : "dbz", "database.server.id" : "1234", "database.server.name" : "MYSQLDB", "database.include.list": "TEST", "database.history.kafka.bootstrap.servers" : "10.96.80.31:9092,10.96.80.32:9092,10.96.80.33:9092", "database.history.kafka.topic" : "mysql.history", "include.schema.changes" : "true" , "database.history.skip.unparseable.ddl" : "true" } }'查看connector 状态
[kafka@node1 debezium-connector-cassandra]$ curl -s localhost:8083/connectors/mysql-connector/status|jq { "name": "mysql-connector", "connector": { "state": "RUNNING", "worker_id": "10.96.80.33:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "10.96.80.33:8083" } ], "type": "source" }reset api 的常用命令
1、查看当前集群的连接器
[kafka@node1 ~]$ curl -s localhost:8083/connectors|jq [ "mysql-connector", "hr-connector" ]2、查看连接器详情
[kafka@node1 ~]$ curl -s localhost:8083/connectors/mysql-connector |jq { "name": "mysql-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.user": "dbz_mysql", "database.server.id": "1234", "database.history.kafka.bootstrap.servers": "10.96.80.31:9092,10.96.80.32:9092,10.96.80.33:9092", "database.history.kafka.topic": "mysql.history", "database.server.name": "MYSQLDB", "database.port": "3307", "include.schema.changes": "true", "database.hostname": "10.96.80.31", "database.password": "dbz", "name": "mysql-connector", "database.history.skip.unparseable.ddl": "true", "database.include.list": "TEST" }, "tasks": [ { "connector": "mysql-connector", "task": 0 } ], "type": "source" }
-
debezium-connector-oracle
- 摘要
- Debezium 介绍
- kafka部署和 plugin组件配置
- 数据库层配置
- standalone 的方式启动服务
- 通过reset api 查看connector信息
- 查看所有的topic
- 模拟操作,查看消息触发情况
- 总结
摘要
本文介绍了通过kafka connector组件+Debezium 实现Oracle 增量数据库抽取,并把增量数据写入kafka topic。该方案可以实现增量数据迁移,可以作为OGG迁移的替代工具,该工具的优势在于数据写入kafka topic,实现下游消息的订阅。当然OGG大数据的组件同样可以实现该功能,如果你考虑法律合规性和作为模块内嵌到应用,可以考虑使用Debezium 项目,目前该项目支持,Oracle ,MySQL ,SQL server ,MongoDB 等主流数据库。 kafka connector 是kafka的一个开源组件,是一个用于与外部系统连接的框架,支持数据库,文件等等。根据功能的不同,社区现在有上百种插件,社区相当活跃。kafka connect 有两个核心概念:source和sink,source负责导入数据到kafka,sink 负责从kafka导出数据,他们都被称为Connetor。Connector 是作为插件方式集成到kafka集群的,你可以根据具体需求,定制开发属于自己的Connector。 Debezium 开源项目就是针对主流数据库-CDC的Connector,本文将介绍Debezium对
Debezium 介绍
- 概念
Debezium是一个分布式平台,它将您现有的数据库转换为事件流,因此应用程序可以看到数据库中的每一个行级更改并立即做出响应。Debezium构建在Apache Kafka之上,并提供Kafka连接兼容的连接器来监视特定的数据库管理系统。Debezium在Kafka日志中记录数据更改的历史,您的应用程序将从这里使用它们。这使您的应用程序能够轻松、正确、完整地使用所有事件。即使您的应用程序停止(或崩溃),在重新启动时,它将开始消耗它停止的事件,因此它不会错过任何东西。
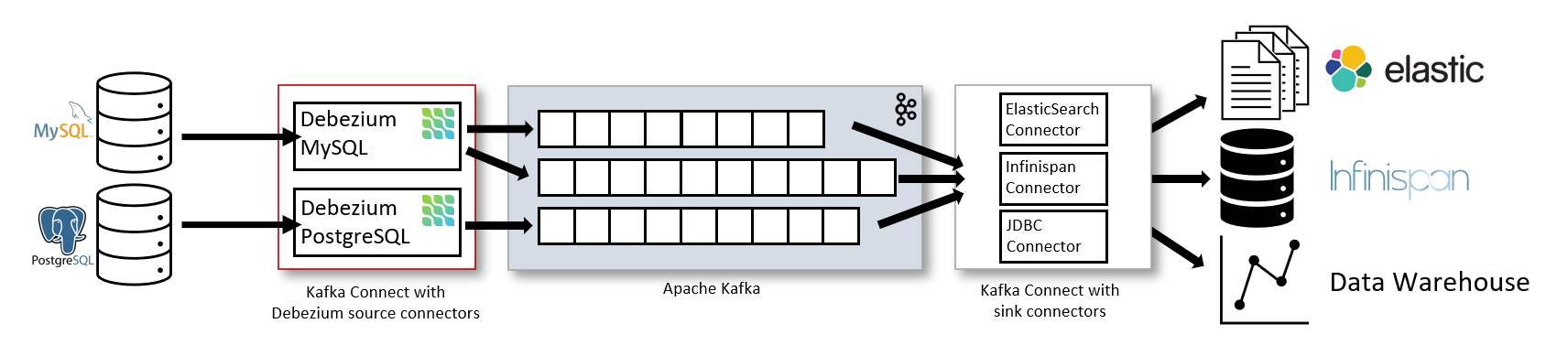
- 插件模式部署
依赖kafka服务,以插件方式和kafka 一起部署。 源连接器,如Debezium,它将数据摄取到Kafka topic 接收连接器,它将数据从Kafka主题传播到其他系统。
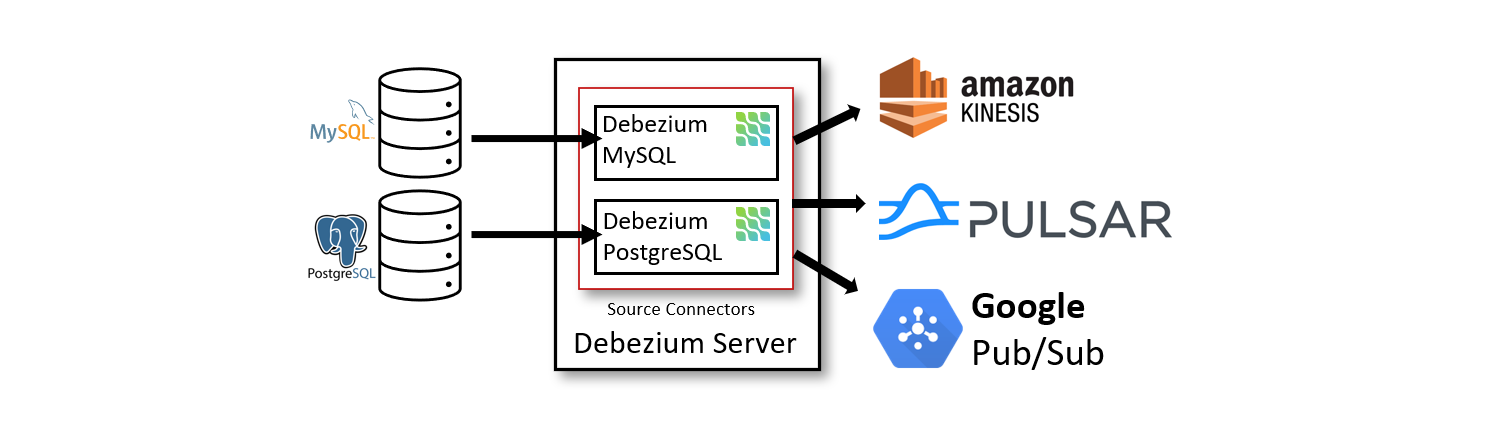
- Debezium server模式部署
不依赖kafka,直接解析数据,并投递到一些支持的公有云组件。
- 内嵌应用程序模式
内嵌模式,既不依赖 Kafka,也不依赖 Debezium Server,用户可以在自己的应用程序中,依赖 Debezium 的 api 自行处理获取到的数据,并同步到其他源上
目前比较常用部署模式,是以插件方式和kafka一起部署,本文将以debezium-connector-oracle举例说明
kafka部署和 plugin组件配置
1、创建kafka用户,配置环境变量
[root@node1 ~]# useradd kafka [root@node1 ~]# su - kafka [kafka@node1 ~]$ vi .bash_profile export KAFKA_HOME=/app/kafka_2.13-2.8.1 export LD_LIBRARY_PATH=/app/instantclient_19_12 export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$KAFKA_HOME/bin --解压二进制安装包 [kafka@node1 ~]$ tar -xzf kafka_2.13-2.8.1.tgz -C /app --创建plugin路径 [kafka@node1 ~]$ cd /app/kafka_2.13-2.8.1 [kafka@node1 ~]$ mkdir -p plugins --解压到文件夹 tar -xvzf debezium-connector-oracle-1.7.0.Final-plugin.tar.gz -C /app/kafka_2.13-2.8.1/plugin/ -- 需要把Oracle连接驱动拷贝kafka libs文件夹下,ojdbc8.jar需要自己下载。 cp ojdbc8.jar /app/kafka_2.13-2.8.1/libs数据库层配置
1、启用数据库的最小附件日志和表级别的全字段附件日志
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; - 示例 ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; -- 创建 用户并赋权 CREATE USER c##dbzuser IDENTIFIED BY dbz DEFAULT TABLESPACE users QUOTA UNLIMITED ON users CONTAINER=ALL; GRANT CREATE SESSION TO c##dbzuser CONTAINER=ALL; GRANT SET CONTAINER TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$DATABASE to c##dbzuser CONTAINER=ALL; GRANT FLASHBACK ANY TABLE TO c##dbzuser CONTAINER=ALL; GRANT SELECT ANY TABLE TO c##dbzuser CONTAINER=ALL; GRANT SELECT_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL; GRANT EXECUTE_CATALOG_ROLE TO c##dbzuser CONTAINER=ALL; GRANT SELECT ANY TRANSACTION TO c##dbzuser CONTAINER=ALL; GRANT LOGMINING TO c##dbzuser CONTAINER=ALL; GRANT CREATE TABLE TO c##dbzuser CONTAINER=ALL; GRANT LOCK ANY TABLE TO c##dbzuser CONTAINER=ALL; GRANT CREATE SEQUENCE TO c##dbzuser CONTAINER=ALL; GRANT EXECUTE ON DBMS_LOGMNR TO c##dbzuser CONTAINER=ALL; GRANT EXECUTE ON DBMS_LOGMNR_D TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOG TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOG_HISTORY TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_LOGS TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_CONTENTS TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOGMNR_PARAMETERS TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$LOGFILE TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$ARCHIVED_LOG TO c##dbzuser CONTAINER=ALL; GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO c##dbzuser CONTAINER=ALL;standalone 的方式启动服务
--zookeeper 配置文件 [kafka@node1 ~]$ vi /app/kafka_2.13-2.8.1/config/zookeeper.properties dataDir=/app/data/zookeeper clientPort=2181 maxClientCnxns=0 admin.enableServer=false --启动zookeeper服务 [kafka@node1 ~]$ zookeeper-server-start.sh -daemon /app/kafka_2.13-2.8.1/config/zookeeper.properties --kafka 配置文件 [kafka@node1 ~]$ vi /app/kafka_2.13-2.8.1/config/server.properties broker.id=0 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/app/data/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=18000 group.initial.rebalance.delay.ms=0 --启动kafka 服务 kafka-server-start.sh -daemon /app/kafka_2.13-2.8.1/config/server.properties --connect 配置文件 [kafka@node1 logs]$ vi /app/kafka_2.13-2.8.1/config/connect-standalone.properties bootstrap.servers=10.96.80.31:9092 key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=true value.converter.schemas.enable=true offset.storage.file.filename=/app/data/connect.offsets offset.flush.interval.ms=10000 plugin.path=/app/kafka_2.13-2.8.1/plugin ---需要注意,standalone 的方式启动connect 时,需要指定连接器的配置信息。 [kafka@node1 logs]$ vi debezium-oracle-connector.properties name=hr-connector connector.class=io.debezium.connector.oracle.OracleConnector tasks.max=1 database.server.name=ORCL database.hostname=10.96.80.21 database.port=1521 database.user=c##dbzuser database.password=dbz database.dbname=orcl database.pdb.name=PDB1 table.include.list=hr.test database.history.kafka.bootstrap.servers=10.96.80.31:9092 database.history.kafka.topic=schema-changes.test --启动connect ,此时连接器worker进程同时启动 [kafka@node1 logs]$ connect-standalone.sh -daemon /app/kafka_2.13-2.8.1/config/connect-standalone.properties /app/kafka_2.13-2.8.1/config/debezium-oracle-connector.properties --后台日志,可以看出执行了闪回查询(as of scn 4842963), [2021-11-07 21:02:27,103] INFO WorkerSourceTask{id=hr-connector-0} Executing source task (org.apache.kafka.connect.runtime.WorkerSourceTask:238) [2021-11-07 21:02:27,106] INFO Metrics registered (io.debezium.pipeline.ChangeEventSourceCoordinator:104) [2021-11-07 21:02:27,106] INFO Context created (io.debezium.pipeline.ChangeEventSourceCoordinator:107) [2021-11-07 21:02:27,143] INFO Snapshot step 1 - Preparing (io.debezium.relational.RelationalSnapshotChangeEventSource:93) [2021-11-07 21:02:27,144] INFO Snapshot step 2 - Determining captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:102) [2021-11-07 21:02:27,743] INFO Snapshot step 3 - Locking captured tables [PDB1.HR.TEST] (io.debezium.relational.RelationalSnapshotChangeEventSource:109) [2021-11-07 21:02:27,749] INFO Snapshot step 4 - Determining snapshot offset (io.debezium.relational.RelationalSnapshotChangeEventSource:115) [2021-11-07 21:02:27,968] INFO Snapshot step 5 - Reading structure of captured tables (io.debezium.relational.RelationalSnapshotChangeEventSource:118) [2021-11-07 21:02:29,215] INFO Snapshot step 6 - Persisting schema history (io.debezium.relational.RelationalSnapshotChangeEventSource:122) [2021-11-07 21:02:32,262] INFO Snapshot step 7 - Snapshotting data (io.debezium.relational.RelationalSnapshotChangeEventSource:134) [2021-11-07 21:02:32,262] INFO Snapshotting contents of 1 tables while still in transaction (io.debezium.relational.RelationalSnapshotChangeEventSource:304) [2021-11-07 21:02:32,262] INFO Exporting data from table 'PDB1.HR.TEST' (1 of 1 tables) (io.debezium.relational.RelationalSnapshotChangeEventSource:340) [2021-11-07 21:02:32,264] INFO For table 'PDB1.HR.TEST' using select statement: 'SELECT "JOB_ID", "JOB_TITLE", "MIN_SALARY", "MAX_SALARY" FROM "HR"."TEST" AS OF SCN 4842963' (io.debezium.relational.RelationalSnapshotChangeEventSource:348)通过reset api 查看connector信息
--查看连接器的名字 [root@node1 ~]# curl -s 10.96.80.31:8083/connectors|jq [ "hr-connector" ] --查看连接器的配置 [root@node1 ~]# curl -s 10.96.80.31:8083/connectors/hr-connector/config |jq { "connector.class": "io.debezium.connector.oracle.OracleConnector", "database.user": "c##dbzuser", "database.dbname": "orcl", "tasks.max": "1", "database.pdb.name": "PDB1", "database.history.kafka.bootstrap.servers": "10.96.80.31:9092", "database.history.kafka.topic": "schema-changes.test", "database.server.name": "ORCL", "database.port": "1521", "database.hostname": "10.96.80.21", "database.password": "dbz", "name": "hr-connector", "table.include.list": "hr.test" } --查看连接器的状态 [root@node1 ~]# curl -s localhost:8083/connectors/hr-connector/status|jq { "name": "hr-connector", "connector": { "state": "RUNNING", "worker_id": "10.96.80.31:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "10.96.80.31:8083" } ], "type": "source" }查看所有的topic
--查看所有topic [kafka@node1 ~]$ kafka-topics.sh --list --zookeeper 10.96.80.31:2181|jq ORCL --表结构信息 ORCL.HR.TEST --表数据,全量数据和增量数据(默认) __consumer_offsets --偏移量 schema-changes.test --历史信息topic,表结构 --查看topic详细信息 [kafka@node1 ~]$kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL.HR.TEST -from-beginning|jq --默认是执行闪回查询,获取所有数据,所以befor是null,after 是表中的数据,"scn": "4842963"。 "payload": { "before": null, "after": { "JOB_ID": "PR_REP", "JOB_TITLE": "Public Relations Representative", "MIN_SALARY": 4500, "MAX_SALARY": 10500 }, "source": { "version": "1.7.0.Final", "connector": "oracle", "name": "ORCL", "ts_ms": 1636290152296, "snapshot": "last", "db": "PDB1", "sequence": null, "schema": "HR", "table": "TEST", "txId": null, "scn": "4842963",--闪回查询指定的scn "commit_scn": null, "lcr_position": null }, "op": "r", "ts_ms": 1636290152296, "transaction": null模拟操作,查看消息触发情况
1、dml 操作模拟
可以看到可以触发实时消息
-查看实时消息 [kafka@node1 ~]$ kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL.HR.TEST |jq "payload": { "before": { "JOB_ID": "AC_ACCOUNT", "JOB_TITLE": "Public Accountant", "MIN_SALARY": 4200, "MAX_SALARY": 9000 }, "after": null, --删除之后afer 是null "source": { "version": "1.7.0.Final", "connector": "oracle", "name": "ORCL", "ts_ms": 1636320665000, "snapshot": "false", "db": "PDB1", "sequence": null, "schema": "HR", "table": "TEST", "txId": "0800050041020000", "scn": "4892329", "commit_scn": "4892347", --提交的scn "lcr_position": null }, "op": "d", --删除操作 可以看到 --模拟触发消息 HR@pdb1 09:24:57> delete from test where rownum =1 ; 1 row deleted. HR@pdb1 09:31:05> commit; Commit complete.ddl 操作模拟
可以看到 ddl可以正常采集
-模拟ddl操作 HR@pdb1 09:35:41> alter table test add (col varchar2(20)) ; Table altered. --查看ORCL topic [kafka@node1 ~]$kafka-console-consumer.sh -bootstrap-server localhost:9092 -topic ORCL -from-beginning|jq "payload": { "source": { "version": "1.7.0.Final", "connector": "oracle", "name": "ORCL", "ts_ms": 1636320952000, "snapshot": "false", "db": "PDB1", "sequence": null, "schema": "HR", "table": "TEST", "txId": "0a001b00c4040000", "scn": "4893263", "commit_scn": "4893054", "lcr_position": null }, "databaseName": "PDB1", "schemaName": "HR", "ddl": "alter table test add (col varchar2(20)) ;"总结
1、 debezium oracle cdc 可以初始化全量数据,闪回查询实现 2、debezium oracle cdc 可以实现增量数据同步 3、debezium oracle cdc 可以实现ddl采集(19C 库) 4、生产环境要部署集群模式,不要采用stanalone模式。
-
原理分析1-统计信息pg_stat_user_tables
摘要
上文介绍了Oracle收集统计信息策略,以及统计信息过期的逻辑,并没有介绍统计信息过期后收集的后台任务。本文会介绍一下,PG统计信息的收集策略,以及统计信息收集的触发阈值;另外PG会回收死堆元,死堆元的回收阈值和统计信息阈值类似。本文并没有介绍统计信息过期后的收集频率和收集方法,只是介绍了统计信息过期过程,或者说统计信息到了应该收集的阈值过程。关于后台任务如何收集过期的统计信息,将和Oracle和MySQL的统计信息收集任务做对比。
结论假设
1、表数据变化信息收集策略,dml ,create as select ,truncate 的表现
- 增删改的变化,会记录到n_tup_ins,n_tup_upd,n_tup_del,n_tup_hot_upd
- create as select 的数据变化,会记录n_tup_ins
- truncate 表,n_live_tup和n_dead_tup记录会更新为0
2、表收集统计信息的判断逻辑,触发统计信息收集的阈值 Autovacuum ANALYZE threshold for a table = autovacuum_analyze_scale_factor * number of tuples + autovacuum_analyze_threshold 3、PG比较特殊,出了收集统计信息,还会触发回收死堆元 表数据的变化量超过阈值之后,autovaccum 就可以进行回收了。 自动回收触发阈值 Autovacuum VACUUM thresold for a table = autovacuum_vacuum_scale_factor * number of tuples + autovacuum_vacuum_threshold insert 触发阈值 Autovacuum VACUUM thresold for a table = autovacuum_vacuum_insert_threshold* number of tuples + autovacuum_vacuum_insert_threshold PG的统计信息记录在文件中,通过内部函数进行读取,这点也是比较特殊。 需要特别注意,触发阈值的计算,应该是dml操作后记录的n_live_tup,本文按照dml之前的行数计算是不准确的。
14beta3版本模拟测试
1、模拟create as select 和truncate 操作。
postgres=# drop table test ; DROP TABLE postgres=# create table test as select * from pg_class; SELECT 398 postgres=# select now(); -[ RECORD 1 ]---------------------- now | 2021-09-25 20:03:36.708725+08 postgres=# select * from pg_stat_user_tables where relname='test'; -[ RECORD 1 ]-------+------- relid | 16434 schemaname | public relname | test seq_scan | 0 seq_tup_read | 0 idx_scan | idx_tup_fetch | n_tup_ins | 398 n_tup_upd | 0 n_tup_del | 0 n_tup_hot_upd | 0 n_live_tup | 398 n_dead_tup | 0 n_mod_since_analyze | 398 n_ins_since_vacuum | 398 last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | vacuum_count | 0 autovacuum_count | 0 analyze_count | 0 autoanalyze_count | 0 --收集万统计信息后,n_mod_since_analyze字段更新为0 postgres=# select now(); -[ RECORD 1 ]---------------------- now | 2021-09-25 20:04:11.683122+08 postgres=# select * from pg_stat_user_tables where relname='test'; -[ RECORD 1 ]-------+------------------------------ relid | 16434 schemaname | public relname | test seq_scan | 0 seq_tup_read | 0 idx_scan | idx_tup_fetch | n_tup_ins | 398 n_tup_upd | 0 n_tup_del | 0 n_tup_hot_upd | 0 n_live_tup | 398 n_dead_tup | 0 n_mod_since_analyze | 0 n_ins_since_vacuum | 398 last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | 2021-09-25 20:04:12.671321+08 vacuum_count | 0 autovacuum_count | 0 analyze_count | 0 autoanalyze_count | 1 postgres=# select now(); -[ RECORD 1 ]---------------------- now | 2021-09-25 20:08:41.931437+08 ---模拟trancate操作 postgres=# truncate table test; TRUNCATE TABLE postgres=# select now(); -[ RECORD 1 ]---------------------- now | 2021-09-25 20:08:55.594144+08 --truncate 操作之后,更新n_live_tup和n_dead_tup postgres=# select * from pg_stat_user_tables where relname='test'; -[ RECORD 1 ]-------+------------------------------ relid | 16434 schemaname | public relname | test seq_scan | 0 seq_tup_read | 0 idx_scan | idx_tup_fetch | n_tup_ins | 398 n_tup_upd | 0 n_tup_del | 0 n_tup_hot_upd | 0 n_live_tup | 0 n_dead_tup | 0 n_mod_since_analyze | 0 n_ins_since_vacuum | 0 last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | 2021-09-25 20:04:12.671321+08 vacuum_count | 0 autovacuum_count | 0 analyze_count | 0 autoanalyze_count | 12、模拟dml操作
--创建测试表 postgres=# create table test as select * from pg_class; SELECT 398 postgres=# select now(); -[ RECORD 1 ]---------------------- now | 2021-09-25 20:30:23.112004+08 --查看统计信息 postgres=# select * from pg_stat_user_tables where relname='test'; -[ RECORD 1 ]-------+------- relid | 16445 schemaname | public relname | test seq_scan | 0 seq_tup_read | 0 idx_scan | idx_tup_fetch | n_tup_ins | 398 n_tup_upd | 0 n_tup_del | 0 n_tup_hot_upd | 0 n_live_tup | 398 n_dead_tup | 0 n_mod_since_analyze | 398 n_ins_since_vacuum | 398 last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | vacuum_count | 0 autovacuum_count | 0 analyze_count | 0 autoanalyze_count | 0 postgres=# --更新398条记录 postgres=# update test set relname =22; UPDATE 398 postgres=# select * from test ; -[ RECORD 1 ]-------+----------------------------------------- oid | 3575 relname | 22 relnamespace | 11 reltype | 0 reloftype | 0 relowner | 10 relam | 403 relfilenode | 3575 reltablespace | 0 relpages | 1 reltuples | 0 relallvisible | 0 reltoastrelid | 0 relhasindex | f relisshared | f relpersistence | p relkind | i relnatts | 2 relchecks | 0 relhasrules | f relhastriggers | f relhassubclass | f relrowsecurity | f relforcerowsecurity | f relispopulated | t relreplident | n relispartition | f relrewrite | 0 relfrozenxid | 0 relminmxid | 0 relacl | reloptions | relpartbound | -[ RECORD 2 ]-------+----------------------------------------- oid | 13714 relname | 22 relnamespace | 99 --删除210条记录 postgres=# delete from test where oid >4000; DELETE 210 --可以看到统计信息,插入了398条,更新了398,删除了210,记录数为188 n_mod_since_analyze和n_ins_since_vacuum记录数为0,是因为统计信息收集了。 postgres=# select * from pg_stat_user_tables where relname='test'; -[ RECORD 1 ]-------+------------------------------ relid | 16445 schemaname | public relname | test seq_scan | 3 seq_tup_read | 1194 idx_scan | idx_tup_fetch | n_tup_ins | 398 n_tup_upd | 398 n_tup_del | 210 n_tup_hot_upd | 2 n_live_tup | 188 n_dead_tup | 0 n_mod_since_analyze | 0 n_ins_since_vacuum | 0 last_vacuum | last_autovacuum | 2021-09-25 20:33:14.00916+08 last_analyze | last_autoanalyze | 2021-09-25 20:33:14.011364+08 vacuum_count | 0 autovacuum_count | 2 analyze_count | 0 autoanalyze_count | 23、模拟统计信息和autovaccum触发阈值 Autovacuum VACUUM thresold for a table = autovacuum_vacuum_scale_factor * number of tuples + autovacuum_vacuum_threshold Autovacuum VACUUM thresold for a table = autovacuum_vacuum_insert_threshold* number of tuples + >autovacuum_vacuum_insert_threshold Autovacuum ANALYZE threshold for a table = autovacuum_analyze_scale_factor * number of tuples + autovacuum_analyze_threshold autovacuum_analyze_threshold 50 autovacuum_vacuum_threshold 50 autovacuum_vacuum_scale_factor | 0.2 autovacuum_analyze_scale_factor | 0.1 autovacuum_vacuum_insert_scale_factor 0.2 autovacuum_vacuum_insert_threshold | 1000
3.1统计信息收集阈值模拟 Autovacuum ANALYZE threshold for a table = autovacuum_analyze_scale_factor * number of tuples + autovacuum_analyze_threshold
``` postgres=# select * from pg_stat_user_tables where relname=’test’;
-[ RECORD 1 ]——-+—————————— relid | 16445 schemaname | public relname | test seq_scan | 3 seq_tup_read | 1194 idx_scan | idx_tup_fetch | n_tup_ins | 799 n_tup_upd | 398 n_tup_del | 210 n_tup_hot_upd | 2 n_live_tup | 401 n_dead_tup | 0 n_mod_since_analyze | 0 n_ins_since_vacuum | 401 last_vacuum | last_autovacuum | 2021-09-25 20:33:14.00916+08 last_analyze | last_autoanalyze | 2021-09-25 20:45:14.656733+08 vacuum_count | 0 autovacuum_count | 2 analyze_count | 0 autoanalyze_count | 3–触发条件 0.1*401 +50 =90
postgres=# insert into test select * from pg_class limit 91 ; select now(); INSERT 0 91 -[ RECORD 1 ]———————- now | 2021-09-25 20:49:51.103724+08 –可以看到n_mod_since_analyze 为91 postgres=# select * from pg_stat_user_tables where relname=’test’; select now(); -[ RECORD 1 ]——-+—————————— relid | 16445 schemaname | public relname | test seq_scan | 3 seq_tup_read | 1194 idx_scan | idx_tup_fetch | n_tup_ins | 890 n_tup_upd | 398 n_tup_del | 210 n_tup_hot_upd | 2 n_live_tup | 492 n_dead_tup | 0 n_mod_since_analyze | 91 n_ins_since_vacuum | 492 last_vacuum | last_autovacuum | 2021-09-25 20:33:14.00916+08 last_analyze | last_autoanalyze | 2021-09-25 20:45:14.656733+08 vacuum_count | 0 autovacuum_count | 2 analyze_count | 0 autoanalyze_count | 3
-[ RECORD 1 ]———————- now | 2021-09-25 20:49:53.112268+08
-
情报分析1-从dba_tab_modifications和dba_tab_statistics说起
假设结论:
1、create as 语法插入的数据不会记录到dba_tab_modifications视图,只会记录到dba_tab_statistics,未标记统计信息过期,但是自动任务会收集。 truncate table 最终会记录到dba_tab_modifications,并标记统计信息为过期。
2、dbms_stat.FLUSH_DATABASE_MONITORING_INFO 可以刷新内存中的刷新到基表视图,收集统计信息的命令也可以触发该刷新动作
3、dba_tab_modifications和dba_tab_statistics 三小时自动从内存刷新一次,超过10%的变化,标记统计信息为过期。
4、收集统计信息,会先触发dbms_stat.FLUSH_DATABASE_MONITORING_INFO把内存的数据变化信息刷到基表视图中。 5、dba_tab_modifications只会记录dml操作,回滚也会记录;同样会记录truncate操作,包含truncate操作删除的记录数。 6、19C中所有这些异步动作,已经变为同步,或者是直接查询内存中pending的变化信息。 create as 完成后直接收集一次统计信息,truncate完成后,直接标记统计信息为过期,dml后,通过视图可以直接查询到数据变化量,数据变化量超过10%,同样会同事标记统计信息为过期。
11G 模拟测试
1、create as 语法插入的数据不会记录到dba_tab_modifications视图,只会记录到dba_tab_statistics,未标记统计信息过期,但是自动任务会收集。
SYS@ora11db 09:13:45> drop table test ; Table dropped. SYS@ora11db 09:13:47> SYS@ora11db 09:13:47> ---创建新表 SYS@ora11db 09:13:47> create table test as select * from user_objects; Table created. --检查数据变化,无数据。 SYS@ora11db 09:13:53> select * from user_tab_modifications where table_name='TEST'; no rows selected --统计信息没有收集,而且未标记过期,19C create table 会同步收集统计信息。 SYS@ora11db 09:13:59> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST因为11G统计信息和表的变更是异步,需要把内存记录更新到基表中。
--从内存中刷新表的变化,期望统计信息和表的变更视图会有变化。 SYS@ora11db 09:14:05> exec dbms_stats.FLUSH_DATABASE_MONITORING_INFO; PL/SQL procedure successfully completed. SYS@ora11db 09:19:15> select * from user_tab_modifications where table_name='TEST'; no rows selected SYS@ora11db 09:19:22> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST可以看到统计信息和表变更视图没有变化,考虑user_tab_modifications只会记录dml操作,create table 不会记录表变化的数据量,推测收集统计信息时会直接收集。
--调用内部收集统计信息的任务,收集统计信息,可以发现表的统计信息被收集。 SYS@ora11db 09:19:28> exec dbms_stats.gather_database_stats_job_proc; PL/SQL procedure successfully completed. SYS@ora11db 09:20:00> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST 9512 09:20:00 NO SYS@ora11db 09:20:09> select * from user_tab_modifications where table_name='TEST'; no rows selected-- 模拟truncate 表操作,看最终表现 SYS@ora11db 09:20:23> truncate table test; Table truncated. -- 统计信息和表变更是异步的没刷新。 SYS@ora11db 09:20:47> select * from user_tab_modifications where table_name='TEST'; no rows selected SYS@ora11db 09:20:51> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST 9512 09:20:00 NO可以看出来,表的统计信息状态没有更新,表数据的变更也没有更新,需要调用内部刷新过程才能看到。
-- 调用刷新内存信息函数包 SYS@ora11db 09:20:57> exec dbms_stats.FLUSH_DATABASE_MONITORING_INFO; PL/SQL procedure successfully completed. --可以看到视图中记录,表被truncate,删除的记录数为9512 SYS@ora11db 09:21:05> select table_name,inserts,updates,deletes,timestamp,truncated from user_tab_modifications where table_name='TEST'; TABLE_NAME INSERTS UPDATES DELETES TIMESTAM TRU ------------------------------ ---------- ---------- ---------- -------- --- TEST 0 0 9512 09:21:05 YES --因为truncate的动作,表的统计信息也标记为过期了。 SYS@ora11db 09:21:13> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST 9512 09:20:00 YES可以看出,truncate 操作,会记录到dba_tab_modifications ,并且更新统计信息为过期状态。
SYS@ora11db 09:21:20> exec dbms_stats.gather_database_stats_job_proc; PL/SQL procedure successfully completed. --统计信息正常 SYS@ora11db 09:21:35> select s.table_name,s.NUM_ROWS,s.LAST_ANALYZED,s.STALE_STATS from user_tab_statistics s where table_name='TEST'; TABLE_NAME NUM_ROWS LAST_ANA STA ------------------------------ ---------- -------- --- TEST 0 09:21:35 NO --记录表变更的视图被更新,相关记录被删除。 SYS@ora11db 09:21:42> select table_name,inserts,updates,deletes,timestamp,truncated from user_tab_modifications where table_name='TEST'; no rows selected11G统计信息标记为过期,Oracle收集统计信息的过程 ,会收集统计信息,收集完成后,dba_tab_modifications信息会清空,因为统计信息已经收集。
-
数据库实例崩溃恢复-MySQL
什么是crash recover?
由于故障导致Instance异常关闭,都会导致数据库实例在重启时执行实例恢复,由后台进程完成,不需要人工干预,恢复的时间检点之间的redo量控制。
为什么要进行crash recover
正常运行期间,里面存在很多脏块,如果实例异常,导致脏块未写入磁盘,如果没有什么手段把崩溃后的脏块找回来,肯定会出现数据不一致的情况。当然关系数据库设计之初,这种情况就已经考虑了,通过重做日志,完全可以实现实例crash不丢数据。 总而言之,所有已提交的事务,都是可以恢复的,这样才能保证数据的一致性。
-
数据库实例崩溃恢复-PostgreSQL
什么是crash recover?
由于故障导致Instance异常关闭或由于执行了pg_ctl stop -m immediate都会导致数据库实例在重启时执行实例恢复,由后台进程完成,不需要人工干预,恢复的时间通过max_wal_size控制。
为什么要进行crash recover
正常运行期间,里面存在很多脏块,如果实例异常,导致脏块未写入磁盘,如果没有什么手段把崩溃后的脏块找回来,肯定会出现数据不一致的情况。当然关系数据库设计之初,这种情况就已经考虑了,通过重做日志,完全可以实现实例crash不丢数据。 总而言之,所有已提交的事务,都是可以恢复的,这样才能保证数据的一致性。
实例恢复的过程
LSN(Log Sequence Number wal日志为了replay的有序性需要加上编号。实现的时候,是按日志的产生的顺序写入磁盘的,即使是写到磁盘缓冲区中,也是按产生的顺序一次写到日志缓冲区中,再将日志顺序写到磁盘。 因此采用日志在日志文件中的偏移来代替这个日志编号,可以通过日志编号迅速定位到日志。这个日志编号就叫做lsn。